今回は、OSSのOptunaを使って、多目的最適化をやっていきます。
具体的には、書籍「Optunaによるブラックボックス最適化」の「3.1 多目的最適化」のサンプルコードを使います。
また、Pythonのmatplotlibで、3Dのグラフで可視化します。この可視化はマウスをドラッグすることで様々な視点から3Dグラフを見ることが出来ます。しかし、Google Colaboratoryの場合、通常の方法では3Dグラフを動かすことが出来ません。その対策についても説明していきます。
この内容が参考になれば幸いです。
【Optuna】
参考文献
参考サイト
◆Optunaの公式サイト
www.preferred.jp
◆Optunaのドキュメント(マニュアル)
optuna.readthedocs.io
◆書籍「Optunaによるブラックボックス最適化」のサンプルコード
github.com
はじめに
Optunaの記事一覧です。良かったら参考にしてください。
Optunaの記事一覧
多目的最適化とは、複数の目的の評価値を改善していく手法です。
一般的なAIの学習のハイパーパラメータのチューニングは、画像分類や回帰問題などの場合、ロスの最小化という1つの目的だけを対象として最適化(単目的最適化)します。
一方、同じハイパーパラメータチューニングの場合でも、目的が推論精度の向上だけでなく、推論時間の短縮も目指す問題を設定することができます。このように、複数の目的を同時に考慮する場合を、多目的最適化と呼びます。
ここでは、【解説】書籍:Optunaによるブラックボックス最適化で説明した内容を、実際に多目的最適化をやってみます。
開発環境の準備
Optunaを実行する環境に必要な内容を説明します。
手順
・書籍のサンプルコードをダウンロードする、もしくは、自分のGitHubにフォークする(フォークしたリポジトリ:
https://github.com/dk0893/optuna-book)
・フォークしたリポジトリをGoogleドライブにクローンする
・chapter3ディレクトリに移動して、このディレクトリに、実際に実行するノートブック(例:ch3-exec.ipynb)を作成する(具体的には、Googleドライブで右クリックして、その他→Google Colaboratoryをクリックする)
Googleドライブ+Google Colaboratory+GitHubの開発環境については、別の記事で詳しく書いているので、必要に応じて参考にしてください。
daisuke20240310.hatenablog.com
多目的最適化のサンプルコードの問題設定
今回解きたい問題は以下になります。
2つの下に凸型の関数が対象です。この最小化問題に取り組みます。
それぞれ、最小値が [0, 0]、[5, 5] なので、両方を同時に満たすことはできませんので、いい感じのところを探す(多目的最適化)のを、Optunaにやってもらうというわけです。
Google Colaboratoryで問題設定を可視化
Google Colaboratoryで、 と
と  を可視化してみます。
を可視化してみます。
の可視化
 f1(x, y)の可視化
f1(x, y)の可視化
の可視化
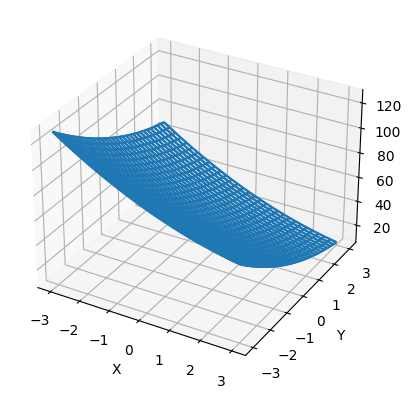 f2(x, y)の可視化
f2(x, y)の可視化
可視化のコードを貼っておきます。
def out_3dgraph( XX, YY, ZZ, show=False, fpath="axes3d.png", debug=False ):
fig = plt.figure()
ax = fig.add_subplot( 111, projection='3d' )
ax.set_xlabel( "X" )
ax.set_ylabel( "Y" )
ax.set_zlabel( "Z" )
ax.plot_wireframe( XX, YY, ZZ )
if show:
plt.show()
if fpath is not None:
fig.savefig( fpath )
return fig, ax
def create_data( func, graph_xlim, graph_ylim ):
xx = np.arange( graph_xlim[0], graph_xlim[1] + 0.1, 0.1 )
yy = np.arange( graph_ylim[0], graph_ylim[1] + 0.1, 0.1 )
XX, YY = np.meshgrid( xx, yy )
ZZ = func( XX, YY )
return XX, YY, ZZ
XX, YY, ZZ = create_data( f1, [-3, 3], [-3, 3] )
fpath = None
fig, ax = out_3dgraph( XX, YY, ZZ, show=False, fpath=fpath, debug=True )
print( f"fig={fig}, ax={ax}" )
ax.plot_wireframe( XX, YY, ZZ )
plt.show()
これは、 の可視化ですが、create_data()の引数をf2に変えると、 の可視化ができます。
の方は、-3から3までの範囲の可視化だとよく分からないので、-30から30まで広げた図です。
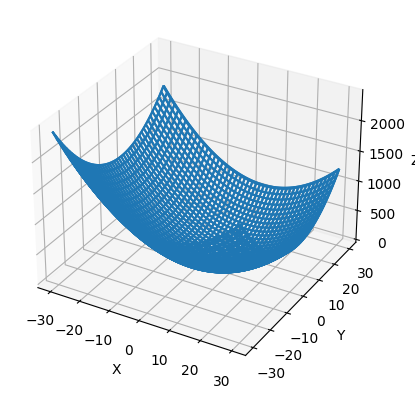 f2(x, y)の可視化範囲を広げた
f2(x, y)の可視化範囲を広げた
は、 を x軸方向に +5、y軸方向に +5 に移動させて、スケールを変更したものでした。
Google Colaboratoryで3Dグラフを動かす方法
Google Colaboratoryで、上の可視化を行うと分かりますが、3Dグラフを他の視点で見たくて、マウスでグリグリ動かしても、Google Colaboratoryでは動きません。
以下のStack overflowでも、結論としては、そのままでは無理で、追加でライブラリ(ipympl)を入れる必要があります。
stackoverflow.com
上の可視化を実行する前に、以下の4行を追加すれば、一応、3Dグラフが動きます。
!pip install ipympl
from google.colab import output
output.enable_custom_widget_manager()
%matplotlib widget
実際にやってみましたが、重すぎて使えませんでした。
仕方ないので、3Dグラフを動かしたいときは、ローカルの環境を使うことにします。
ローカルで3Dグラフを動かす方法
上の可視化と同じようなソースコードをGitHubにあげておきました。
github.com
コマンドプロンプトを開いて、ソースコードを置いた場所まで移動します。
を可視化する場合は以下です。
python axes3d.py --pat 1 --show
を可視化する場合は以下です。
python axes3d.py --pat 2 --show
動かしたイメージです。
 3Dグラフを動かしたイメージ
3Dグラフを動かしたイメージ
多目的最適化のサンプルコードの説明
だいぶ前置きが長くなりました。
書籍の3.1章のサンプルコード(https://github.com/dk0893/optuna-book/tree/master/chapter3)は複数あるので、それらについて説明します。
- binh_and_korn.py:最適化問題の関数であり、3と4で使われる
- list_3_1_optimize_binh_and_korn.py:今回の最適化問題を解く
- list_3_2_print_multi_objective_optimization_result.py:今回の最適化問題を解き、結果をログ出力する
- list_3_4_optimize_with_storage.py:今回の最適化問題を1000トライアルで解き、スタディをデータベースに保存する
- list_3_5_plot_pareto_front.py:4の学習結果(データベース)をロードして、パレートフロントを可視化する
- list_3_6_plot_slice.py:4の学習結果(データベース)をロードして、散布図を作成する
1は、3、4で使われる関数が定義されているファイルです。
2から4までは、表示の有無、トライアル数が異なる、の違いはありますが、今回の同じ問題を解いています。同じ問題を何度も解いている理由は、書籍では切り取ったコード(それだけでは動かない)が掲載されていますが、GitHubでは動くコードとするためだと思います。
ここでは、4のサンプルコード(1をインポートしてる)を使い、その後、5と6で可視化を行います。
1のbinh_and_korn.pyは以下の通りです。
def f1(x, y):
return 4 * x**2 + 4 * y**2
def f2(x, y):
return (x - 5)**2 + (y - 5)**2
def objective(trial):
x = trial.suggest_float("x", 0, 5)
y = trial.suggest_float("y", 0, 3)
objective0 = f1(x, y)
objective1 = f2(x, y)
return objective0, objective1
まず、今回の問題設定通りの と が定義されています。
objective(trial)は目的関数(最適化の対象)です。
単目的最適化と同じような記述で、多目的最適化を実現できています。単目的最適化との違いは、複数の関数が最適化対象とされていることと、目的関数が複数の評価値を返しているところです。
続いて、4のlist_3_4_optimize_with_storage.pyです。
import optuna
from binh_and_korn import objective
study = optuna.create_study(
study_name="ch3-multi-objective-example",
storage="sqlite:///optuna.db",
directions=["minimize", "minimize"],
load_if_exists=True,
)
if len(study.trials) == 0:
study.optimize(objective, n_trials=1000)
こちらも、単目的最適化と同じような記述で、単目的最適化を実現できています。違いは、directionsが最適化対象の数だけ指定されていることだけです。
Google ColaboratoryでOptunaの多目的最適化を実行する
では、実際に、Google Colaboratoryを使って、多目的最適化を実行してみます。
[I 2024-04-09 16:29:29,078] Using an existing study with name 'ch3-multi-objective-example' instead of creating a new one.
[I 2024-04-09 16:29:29,358] Trial 0 finished with values: [35.94472613687067, 19.25332909284121] and parameters: {'x': 2.7257920381467535, 'y': 1.2474932059908925}.
[I 2024-04-09 16:29:29,518] Trial 1 finished with values: [78.01560715095809, 9.013826159413323] and parameters: {'x': 3.8018889948518386, 'y': 2.247118567980781}.
[I 2024-04-09 16:29:29,693] Trial 2 finished with values: [114.16771767594246, 6.454634890846881] and parameters: {'x': 4.735523260179394, 'y': 2.4732061926344793}.
[I 2024-04-09 16:29:29,934] Trial 3 finished with values: [37.44927077348942, 22.72686345669807] and parameters: {'x': 0.6803529018306304, 'y': 2.983192521836798}.
[I 2024-04-09 16:29:30,410] Trial 4 finished with values: [87.34795493867823, 20.063135573884196] and parameters: {'x': 4.64226629673557, 'y': 0.5351190193429662}.
・・・途中割愛・・・
[I 2024-04-09 16:35:00,278] Trial 995 finished with values: [119.2924174064566, 4.589777455914955] and parameters: {'x': 4.634259311934727, 'y': 2.8890733776351922}.
[I 2024-04-09 16:35:00,705] Trial 996 finished with values: [88.28877476344911, 8.244742247503098] and parameters: {'x': 4.113998146843409, 'y': 2.268746997492509}.
[I 2024-04-09 16:35:01,786] Trial 997 finished with values: [76.00513750761637, 14.486585076302251] and parameters: {'x': 4.164835756797107, 'y': 1.286634173263077}.
[I 2024-04-09 16:35:02,261] Trial 998 finished with values: [90.96117247768643, 12.614097486129241] and parameters: {'x': 4.533479731728605, 'y': 1.479139831600632}.
[I 2024-04-09 16:35:02,655] Trial 999 finished with values: [1.895490252956519, 42.6918557152175] and parameters: {'x': 0.09663406469405056, 'y': 0.6815676201081121}.
無事に成功したようです。
多目的最適化の結果を可視化する
2つの可視化が紹介されています。1つずつ見ていきます。
パレートフロントの可視化
まず、5のパレートフロントを可視化するコード(以下)を実行します。
import optuna
study = optuna.load_study(
study_name="ch3-multi-objective-example",
storage="sqlite:///optuna.db"
)
optuna.visualization.plot_pareto_front(
study,
include_dominated_trials=True
).show()
optuna.visualization.plot_pareto_front(
study,
include_dominated_trials=False
).show()
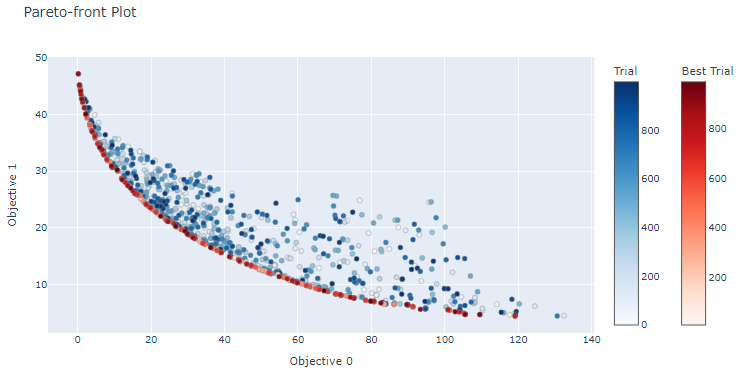 全てのトライアルをプロット
全てのトライアルをプロット
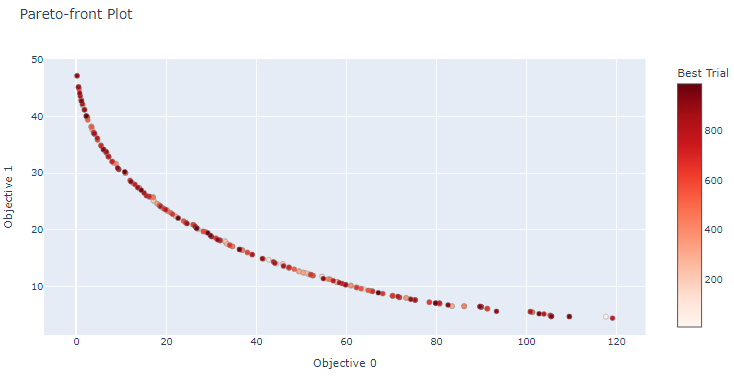 ベストトライアルだけをプロット
ベストトライアルだけをプロット
横軸が、 の評価値で、縦軸が の評価値の散布図です。
各プロットは、トライアルの評価値であり、色が濃いほど、後半に実行されたトライアルを示しています。赤のプロットはベストなトライアルのプロットです。
赤のベストなトライアルは、パレート解と呼ばれ、他の評価値よりも良いものになります。多目的最適化なので、解が複数あるということになります。
なお、書籍によると、Optunaの可視化関数で、多目的最適化をサポートしているのは、この plot_pareto_front関数だけとのことです。
パレート解とは
青のプロットはパレート解(ベスト)ではなく、赤のプロットはパレート解(ベスト)です。この違いをもう少し詳しく説明します。
例えば、どれでもいいですが、赤のプロットの1つ(プロットAとします)に注目します。プロットAの の評価値(Objective 0)を取り出したところ、60ぐらいで、 の評価値は10でした。
の評価値(Objective 0)が、プロットAの60より小さい値を持つ他のプロットは、全て、 の評価値(Objective 1)が、プロットAの10より大きな値になっています。このようなプロットAのことをパレート解と言います。
同様に、 の評価値(Objective 1)が、プロットAの10より小さい値を持つ他のプロットは、全て、 の評価値(Objective 0)は、プロットAの60より小さな値になっています。
図で見ると分かりやすいですが、文章で説明するのは難しいですね。
単目的最適化の可視化を活用する
続いて、6の可視化のコード(以下)を実行します。
import optuna
study = optuna.load_study(
study_name="ch3-multi-objective-example",
storage="sqlite:///optuna.db"
)
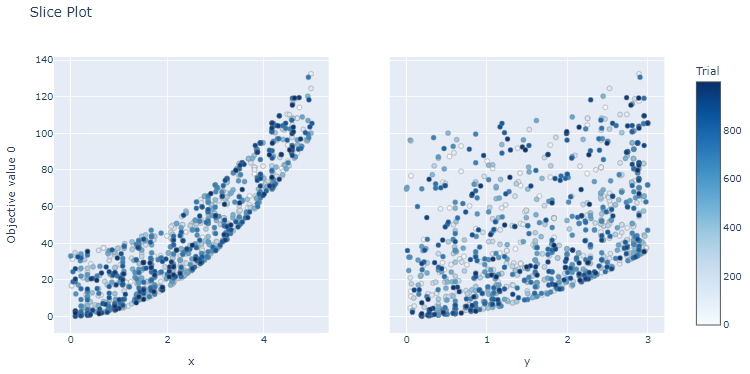
optuna.visualization.plot_slice(
study,
target=lambda t: t.values[0],
target_name="Objective value 0",
).show()
optuna.visualization.plot_slice(
study,
target=lambda t: t.values[1],
target_name="Objective value 1",
).show()
 f1(x, y)の可視化
f1(x, y)の可視化
 f2(x, y)の可視化
f2(x, y)の可視化
は、 と
と  ともに、小さい値の方が評価値は良い傾向です。一方、 は、 と ともに、5 に近づくと評価値は良くなっています。
ともに、小さい値の方が評価値は良い傾向です。一方、 は、 と ともに、5 に近づくと評価値は良くなっています。
書籍では、この plot_slice関数は、多目的最適化には対応しておらず、単目的最適化にしか対応していないが、1つずつ見ることで、単目的最適化用の可視化関数も活用できると述べられています。
3.1章の内容は以上になります。
おわりに
Optunaの多目的最適化は、デフォルトで、NSGAIISamplerが使われるとのことです(単目的最適化のデフォルトはTPESampler)。まだ、それぞれのサンプラーの特徴は見えてこないですね。
進めていくうちに分かってくると期待します!
今回は以上です!
最後までお読み頂いて、ありがとうございました。