今回は、OSSのOptunaの実行結果を可視化する「Optuna Dashboard」を、「Google Colaboratory」で使う方法を説明します。
今回の使い方は、Google ColaboratoryでOptuna Dashboardを起動(サーバを起動)し、ブラウザからOptuna Dashboardを使えるというものです。
手元にLinuxがあれば、コマンドラインからOptuna Dashboardを起動して、ブラウザでアクセスすると普通に使えます。ここでは、手元にLinuxが無く、Google ColaboratoryでOptunaを実行している状況で、Optuna Dashboardを使うことを想定しています。
この内容が参考になれば幸いです。
【Optuna】
参考文献
参考サイト
◆Optunaの公式サイト
www.preferred.jp
◆Optuna Dashboardのドキュメント(マニュアル)
optuna-dashboard.readthedocs.io
はじめに
Optunaの記事一覧です。良かったら参考にしてください。
Optunaの記事一覧
ここでは、スタディを保存したストレージが必要になります。
以下では、sqlite:///optuna.dbとしているので、適宜読み替えてください。
「ch2-rf」の学習を記録した「optuna.db」を以下からダウンロード頂けます。
https://github.com/dk0893/optuna-book/raw/master/chapter2/optuna.db
Google Colaboratoryで、Optuna Dashboardを起動する方法
Google Colaboratoryで、Optuna Dashboardを使用する方法について説明します。
以下で、2つの方法を紹介していますが、まず、公式サイトの方法で試します。
もし、うまくいかなかった場合は、Stack overflowで回答されていた内容を試すといいと思います。
公式サイトの方法で、Optuna Dashboardを起動する
Optuna Dashboardの公式サイト(マニュアル)に、Google Colaboratoryという項目があります。
そこに書かれているソースコードは以下の通りで、これを1つのGoogle Colaboratoryのセルで実行します。
公式のソースコードにはスタディを実行するコードも含まれていますが、ここでは、Optuna Dashboardを起動する部分だけにしています。
ポート番号の指定と、データベースファイルの指定を、必要に応じて変更します。
import optuna
import threading
from google.colab import output
from optuna_dashboard import run_server
port = 8081
storage = optuna.storages.RDBStorage("sqlite:///optuna.db")
thread = threading.Thread(target=run_server, args=(storage,), kwargs={"port": port})
thread.start()
output.serve_kernel_port_as_window(port, path='/dashboard/')
実行結果
https://localhost:8081/dashboard/
Bottle v0.12.25 server starting up (using WSGIRefServer())...
Listening on http://localhost:8081/
Hit Ctrl-C to quit.
https://localhost:8081/dashboard/がリンクになっているので、それをクリックすると、ブラウザの別のウィンドウで、Optuna Dashboardが起動します。
 Google ColaboratoryでOptuna Dashboardを起動できた
Google ColaboratoryでOptuna Dashboardを起動できた
Stack overflowに書かれていた方法で、Optuna Dashboardを起動する
Stack overflowの記事(https://stackoverflow.com/questions/76033104/launching-optuna-dashboard-in-google-colaboratory)に、Optuna Dashboardの開発者の方が、Google ColaboratoryでOptuna Dashboardを使う方法を回答していました。
そこに記載されていたソースコードは以下の通りで、これも1つのGoogle Colaboratoryのセルで実行します。
公式サイトの方法と同様に、ポート番号の指定と、データベースファイルの指定は、必要に応じて変更します。
import optuna
import time
import threading
from optuna_dashboard import wsgi
from wsgiref.simple_server import make_server
port = 8081
storage = optuna.storages.RDBStorage("sqlite:///optuna.db")
app = wsgi(storage)
httpd = make_server("localhost", port, app)
thread = threading.Thread(target=httpd.serve_forever)
thread.start()
time.sleep(3)
from google.colab import output
output.serve_kernel_port_as_window(port, path='/dashboard/')
実行結果
https://localhost:8081/dashboard/
上記はリンクになっているので、それをクリックすると、ブラウザの別のウィンドウで、Optuna Dashboardが起動します。
Optuna Dashboardの使い方
過去の記事で最適化したスタディの「ch2-rf」を開いてみます。
history画面
 Optuna Dashboardでch2-rfを参照する
Optuna Dashboardでch2-rfを参照する
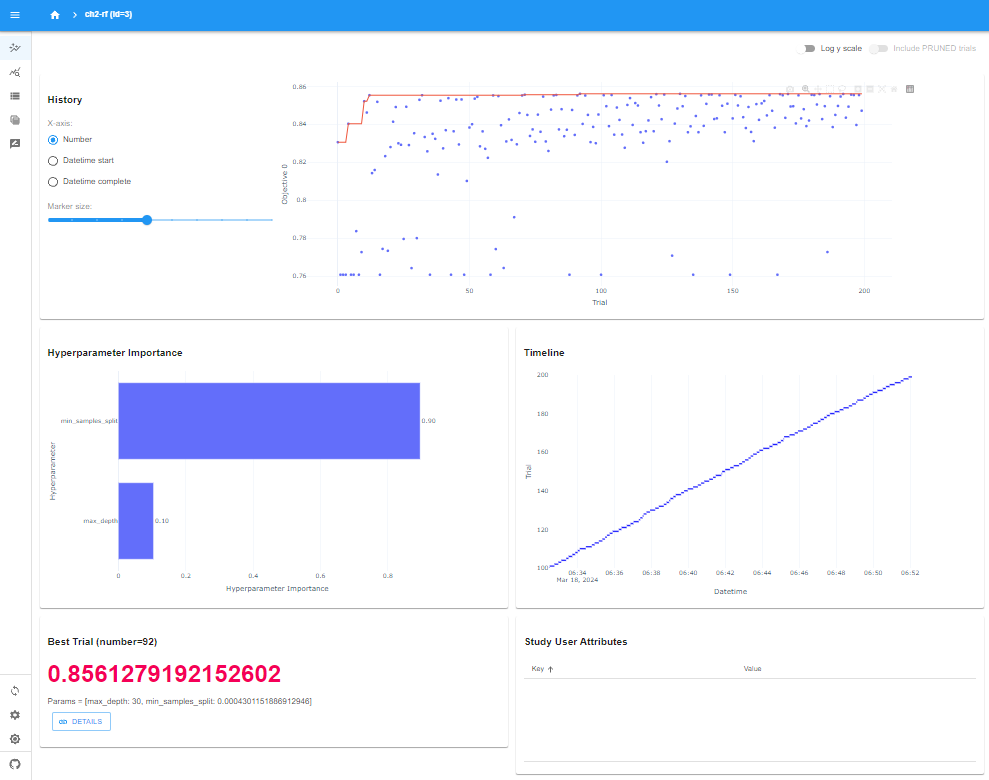
一番上のHistoryは、200回のトライアルの評価結果(分類精度)がプロットされ、赤線は精度の最高値を結んだものとなっています。早い段階で、ほぼ最高点に達していることが分かります。
次の左側のHyperparameter Importanceは、どのハイパーパラメータが重要だったかが可視化されています。max_depthよりも、min_samples_splitの方が、分類精度には重要なハイパーパラメータだったということになります。
その右側のTimelineは、トライアルの処理時間が可視化されており、どのトライアルも、処理時間としては大きく変わりがなかったことが分かります。
最後に、左下のBest Trialは、92回目の最高精度が表示されています。
Analyticsの画面
続いて、Analyticsの画面です。
Hyperparameter Relationships
 Analyticsの画面(max_depth)
Analyticsの画面(max_depth)
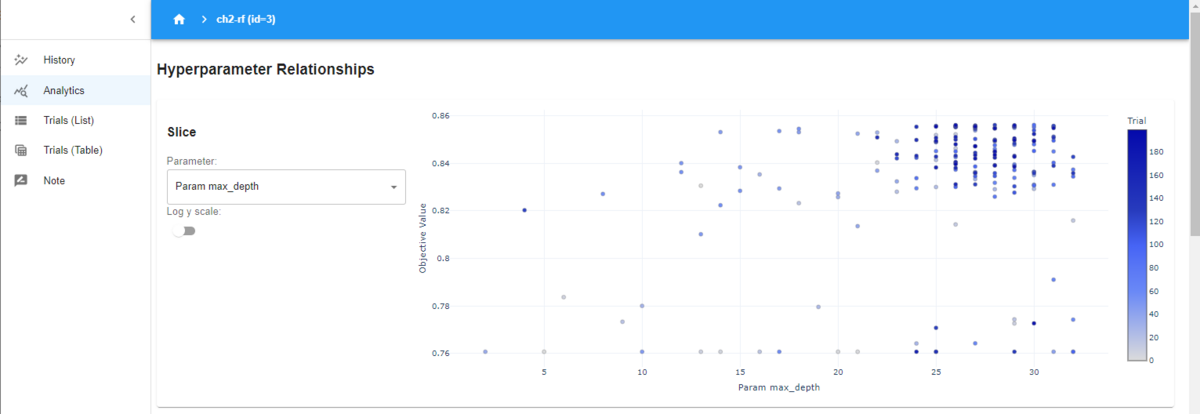
Hyperparameter Relationshipsと書かれてるグラフでは、横軸に選択したハイパーパラメータ、縦軸に評価値の散布図です。Parameterのところで、ハイパーパラメータを変更することができます。
この図では、「max_depth」が選択されていて、サンプルされた値が変化しても、評価値は依存していないことが分かります。先ほどの重要度が小さかった理由ですね。
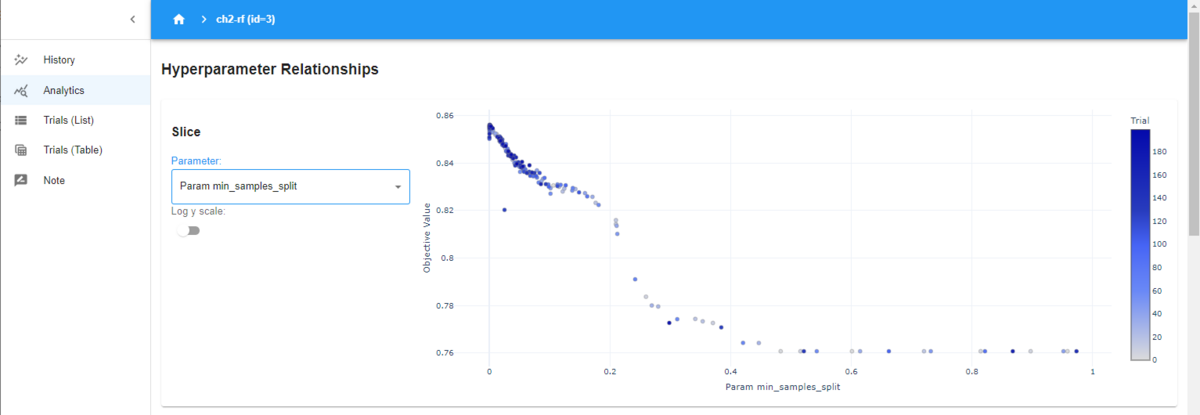
一方で、以下は、「min_samples_split」を選択したときの図になります。
 Analyticsの画面(min_samples_split)
Analyticsの画面(min_samples_split)
「min_samples_split」が小さい値になるほど、評価値が高くなっていることが分かります。このハイパーパラメータによって評価値が左右されているので、重要度が高いと判定されたということになります。
Parallel Coordinate
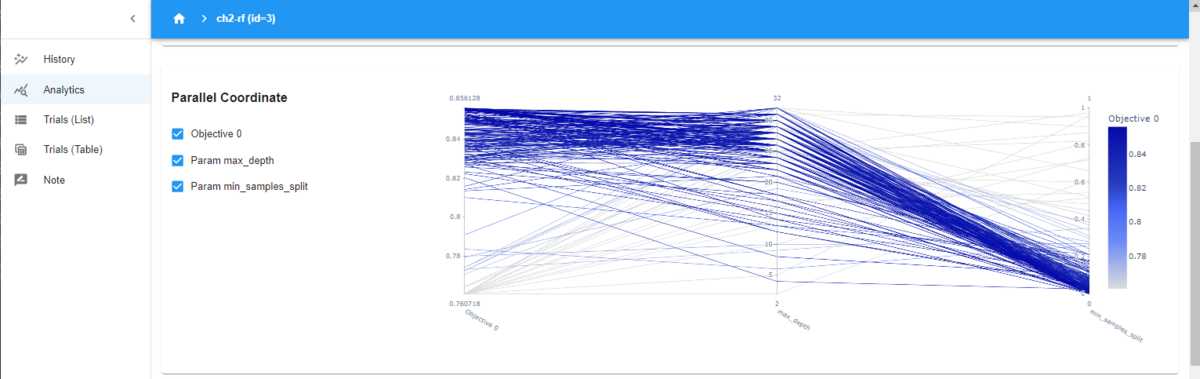
下の図のParallel Coordinateは、並行座標のプロットで、高次元データを2次元で表現する可視化方法です。
 Parallel Coordinateのプロット
Parallel Coordinateのプロット
横軸は、左から「Objective 0」、「max_depth」、「min_samples_split」となっています。「Objective 0」は評価値です。0が付いている理由は、今回は評価値が1つしかありませんが、多目的最適化では評価値が複数存在し、それらを識別する番号になります。
見方としては、評価値が高いほど、濃い青色で示されています。「Objective 0」が高いときのパラメータは、各パラメータにおいて、どのぐらいの値がいいのかを確認することが出来ます。例えば、「Objective 0」が高いところから右に進むと、「max_depth」の大きな値のところにつながっています。「max_depth」が高い値の方が、評価値が高くなっているということが分かります。一方、さらに右に進むと、「min_samples_split」は小さな値につながっています。「min_samples_split」は小さい値の方が、評価値が高くなることが分かります。
Contour
下の図のContourは等高線図です。
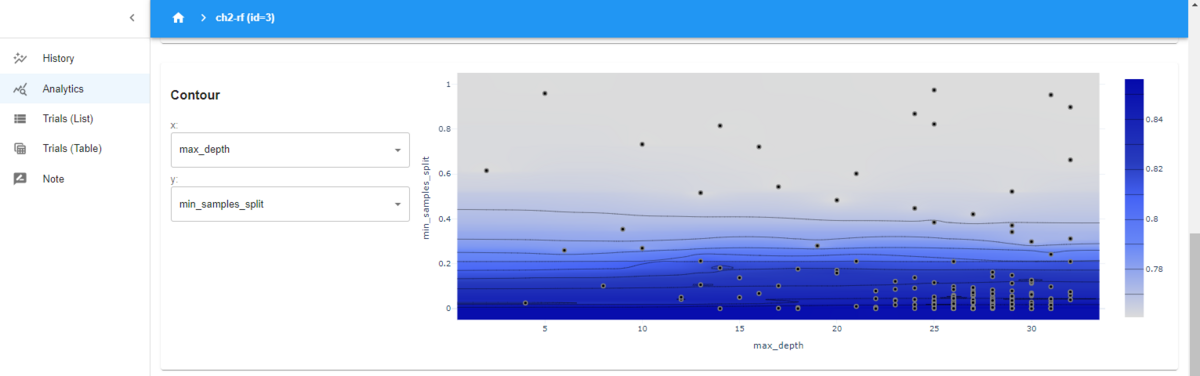 Analyticsの画面のContour
Analyticsの画面のContour
等高線図では、選択した2つのパラメータについて、評価値の高さの形状が分かります。この場合は、「min_samples_split」が低い値ほど、評価値が高くなることが分かり、一方で、「max_depth」は、高い値の方が評価値は高いですが、低い値と、そこまで差はないということが分かります。
Rank
下の図はRankです。
 Analyticsの画面のRank
Analyticsの画面のRank
どういう目的のグラフかは分かりませんが、図を貼っておきます。等高線図と似てますね。
Empirical Distribution of the Objective Value(EDF)
下の図はEDFです。
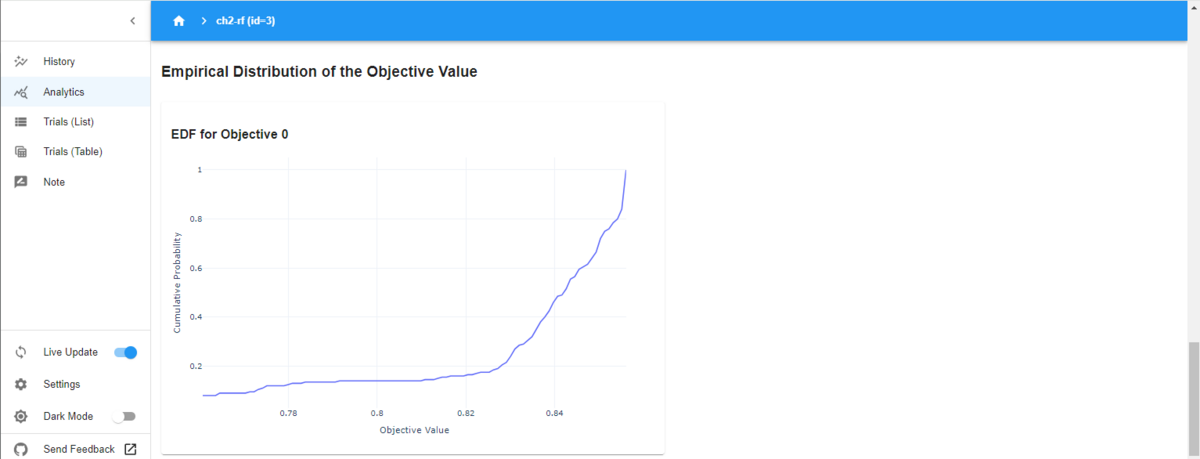 Analyticsの画面の
Analyticsの画面の
全然知らないのですが、横軸が評価値、縦軸が蓄積確率となっています。右の方で急激に上がっているのは、トライアルの多くが、高い評価値を出していることを示しているのだと思います。
Trials (List) の画面
続いて、Trials (List) の画面です。
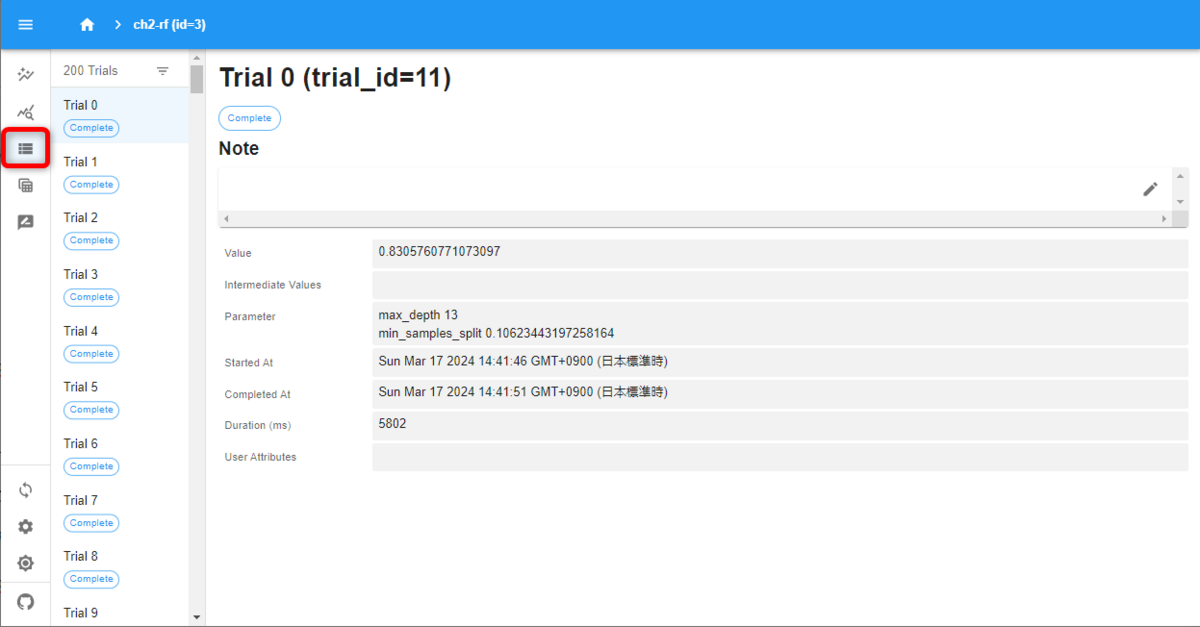 Traials(List)の画面
Traials(List)の画面
各トライアルの詳細な結果が確認できます。
画面上部は、Markdownか、HTMLでノート(メモ)が記入できるようですが、このときは、なぜかエラーが出て書けませんでした。
Trials (Table) の画面
続いて、Trials (Table) の画面です。
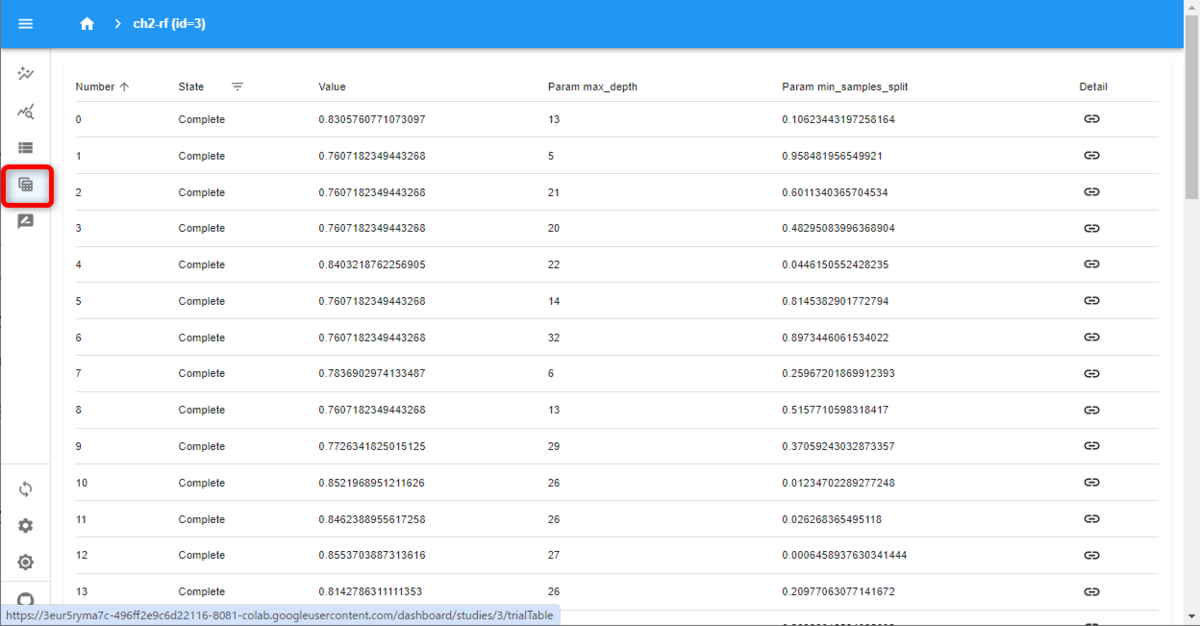 Trials (Table) の画面
Trials (Table) の画面
各トライアルの結果が一覧になっています。右端の列のリンクマークをクリックすると、Trials (List) にジャンプしました。
Optuna Dashboardで、データベースを変更できると書いてあったと思うのですが、変更する方法が分かりませんでした。
5番目はノートの画面で、自由にメモできるようでした。
今回は以上です!