今回は、OSSのOptunaを、Google Colaboratoryで使う手順の詳細説明と、実際の実行結果を記載します。
プログラムは、書籍「Optunaによるブラックボックス最適化」の2章のサンプルコードを使用します。
また、トライアル(学習)の再現性を確保(同じ学習結果を再現する)し、Optunaのスタディも再現させる方法についても説明します。
この内容が参考になれば幸いです。
【Optuna】
参考文献
参考サイト
◆Optunaの公式サイト
www.preferred.jp
◆Optunaのドキュメント(マニュアル)
optuna.readthedocs.io
◆書籍「Optunaによるブラックボックス最適化」のサンプルコード
github.com
はじめに
Optunaの記事一覧です。良かったら参考にしてください。
Optunaの記事一覧
ここでは、書籍「Optunaによるブラックボックス最適化」の2章のサンプルコードを使って、実際に、ハイパーパラメータのチューニングをやっていきます。
開発環境の準備
Optunaを実行する環境に必要な内容を説明します。
手順
・書籍のサンプルコードをダウンロードする、もしくは、自分のGitHubにフォークする(フォークしたリポジトリ:
https://github.com/dk0893/optuna-book)
・フォークしたリポジトリをGoogleドライブにクローンする
・chapter2ディレクトリに移動して、このディレクトリに、実際に実行するノートブック(例:ch2-exec.ipynb)を作成する(具体的には、Googleドライブで右クリックして、その他→Google Colaboratoryをクリックする)
Googleドライブ+Google Colaboratory+GitHubの開発環境については、別の記事で詳しく書いているので、必要に応じて参考にしてください。
daisuke20240310.hatenablog.com
Google ColaboratoryでOptunaを実行する
list_2_12_rf.pyを実行する
list_2_12_rf.py(https://github.com/dk0893/optuna-book/blob/master/chapter2/list_2_12_rf.py)のソースコードは以下の通りで、まずは、Optunaを使わずに学習を実行する実装になっています。
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
data = fetch_openml(name="adult")
X = pd.get_dummies(data["data"])
y = [1 if d == ">50K" else 0 for d in data["target"]]
clf = RandomForestClassifier(
max_depth=8,
min_samples_split=0.5,
)
score = cross_val_score(clf, X, y, cv=3)
accuracy = score.mean()
print(f"Accuracy: {accuracy}")
データセットのダウンロードと前処理
adultというOpenMLのデータセットを使用しています。OpenMLとは、機械学習のデータセット、その実行ソースコード、結果を共有するプラットフォームです。以下で、OpenMLについて少し調べてみます。
OpenML(https://www.openml.org/)にアクセスします。左のサイドバーのDatasetsをクリック、Searchに「adult」と入力してEnterを押すとadultのデータセットが見つかります。v1からv4までの4種類があるようです。
list_2_12_rf.pyでは、data = fetch_openml(name="adult")でデータのダウンロードを行っています。scikit-learnのマニュアルのfetch_openml(https://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_openml.html)によると、バージョンは指定しておらず、その場合は一番古いバージョンがダウンロードされるらしいです。つまり、v1がダウンロードされることになります。
adultデータセットのv1を見てみます。Data Detailが表示されます。
 OpenML adult v1 データセット
OpenML adult v1 データセット
adultは、UCIのデータセットであり、v2がオリジナルのバージョンらしく、v1は「いくつかの特徴量が離散化されている」と書かれています。
続いて、Analysisを見てみます。データセットの分析が簡易的に(十分に?)行えるようです。
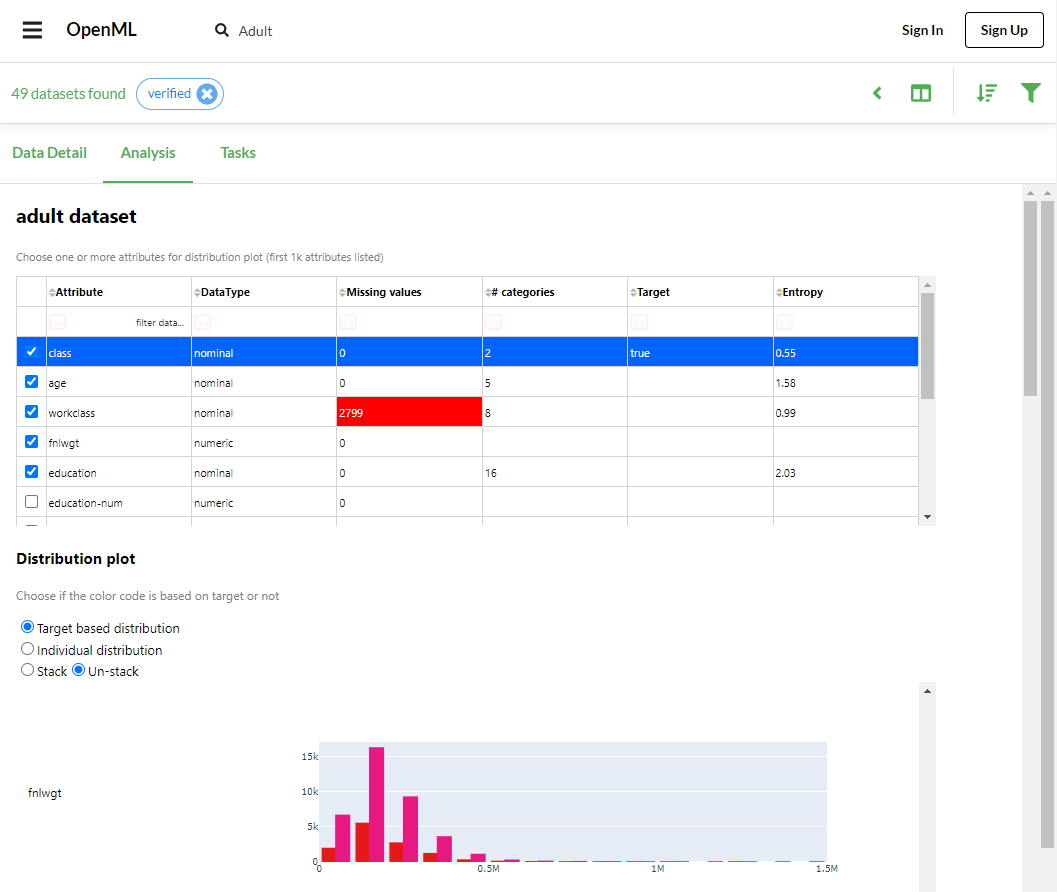 OpenML adult v1 データセット Analysis
OpenML adult v1 データセット Analysis
adultのデータセットは、48842のサンプル数を持ち、15の特徴量を持ち(ただし、そのうちの1つは正解ラベルなので、学習で使用する特徴量は14)、48842×15のテーブルデータです。学習で使用する14個の特徴量のうち、2個は数値データで、12個は数値以外のデータ(文字列)です。
ここで、adultのデータセットについて少し説明しておきます。全部で48842人分のサンプルがあり、1サンプルは、ある人の年齢、雇用クラス、最高学歴、人種(白人、黒人など)、労働時間、出身国などの特徴を持ち、正解ラベルは、年間50Kドルを超える収入を持っているかどうかであり、これを予測する分類問題です。
taskは、adultのデータセットを使った評価方法(分類、クラスタリングなど)が書かれています。
X = pd.get_dummies(data["data"])では、14個の特徴量のうち、数値以外のデータを数値データに変換(OneHot表現など)しており、結果的に、特徴量は14個から121個に増えています。
y = [1 if d == ">50K" else 0 for d in data["target"]]では、正解ラベルを、手動で、0と1のデータに変換してリストに格納しています。
機械学習モデルの初期化
ここでは、scikit-learnのRandomForestClassifier(https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html)を使用しています。引数のmax_depthは、決定木の最大の深さであり、8を指定している。引数のmin_samples_splitは分岐するために必要なサンプル数の最小値であり、0.5を指定しています。
ランダムフォレストとは、決定木を複数(デフォルト100個)学習させて、そのアンサンブル(平均など)で予測する過学習に強く、非常に優秀なモデルです。
決定木とは、エントロピーや、ジニ不純度といった(複数の方式が存在し、RandomForestClassifierのデフォルトはジニ不純度)、各クラスの混在具合を指標とし、木構造で分類する手法です。エントロピーとジニ不純度は、複数のサンプルの中に、クラスの混在があれば高い値を示し、クラスの混在が少ないと小さい値を示す指標です。例えば、2クラスの場合で、クラスのサンプル数が同じ数ずつあった場合は0.5、片方のクラスしか存在しない場合は0という値になります。以下に、ジニ不純度の式を示します。
 はノード、
はノード、 はクラス数を示します。
はクラス数を示します。 は、全クラスの確率の和であるため、1になるため、式変形が可能です。
は、全クラスの確率の和であるため、1になるため、式変形が可能です。
決定木の具体的な手順としては、まず、親ノードに全サンプルがある状態を初期状態とし、全特徴量で分岐(数値の場合は平均値を閾値とする)させてみて、一番エントロピーやジニ不純度が減少した分岐を採用します(この状態で、親ノード+子ノード2つ)。同様に、全ての子ノードについて、同様の操作を行い、エントロピーや、ジニ不純度が0になる(他のクラスが混在しない状態)まで繰り返します。
交差検証による評価
ここでは、scikit-learnのcross_val_score(https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html)を使って交差検証を実行します。引数のclfはモデルのインスタンス、Xは学習データセット、yは正解ラベル、cvはクロスバリデーションの分割数です。
交差検証は、クロスバリデーションとも呼ばれ、指定した学習データと正解ラベルを使い、汎化性能を高める学習手法です。
具体的には、学習データを指定した分割数で分割(データセット0、1、2とする)し、最初は先頭のデータセット0を検証データとし、データセット1と2を使って学習を行い、検証データで推論した結果(分類精度)を保持しておきます。次にデータセット1を検証データとして、同様に学習と推論を繰り返します。データセット2も同様に行い、cross_val_scoreは3回の結果を返します。その後、平均を計算して、Accuracy(正答率)を表示しています。
実行結果
実際にGoogle Colaboratoryで実行してみました。
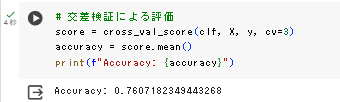 list_2_12_rf.pyの実行結果
list_2_12_rf.pyの実行結果
約0.76の分類精度で、書籍に書かれてる精度と、全く同じ精度になりました。
list_2_14_optimize_rf.pyを実行する
list_2_14_optimize_rf.py(https://github.com/dk0893/optuna-book/blob/master/chapter2/list_2_14_optimize_rf.py)のソースコードは以下の通り(説明しやすいように、一部コメントを追加しています)で、Optunaのブラックボックス最適化を使った実装となっています。
import optuna
import pandas as pd
from sklearn.datasets import fetch_openml
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
data = fetch_openml(name="adult")
X = pd.get_dummies(data["data"])
y = [1 if d == ">50K" else 0 for d in data["target"]]
def objective(trial):
clf = RandomForestClassifier(
max_depth=trial.suggest_int(
"max_depth", 2, 32,
),
min_samples_split=trial.suggest_float(
"min_samples_split", 0, 1,
),
)
score = cross_val_score(clf, X, y, cv=3)
accuracy = score.mean()
return accuracy
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
print(f"Best objective value: {study.best_value}")
print(f"Best parameter: {study.best_params}")
データのダウンロードと前処理
list_2_12_rf.pyと同じです。
objectiveメソッドの定義
objectiveメソッドの内容としては、list_2_12_rf.pyの機械学習モデルの初期化とよく似ていますが、RandomForestClassifierの引数の指定方法が変更されています。
まず、引数のmax_depthには、trial.suggest_int("max_depth", 2, 32,)が指定されており、max_depthの探索範囲として、整数の2から32が指定されています。
Optunaのマニュアルのsuggest_int(https://optuna.readthedocs.io/en/stable/reference/generated/optuna.trial.Trial.html#optuna.trial.Trial.suggest_int)を見ます。suggest_int(name, low, high, *, step=1, log=False)とあり、2<=max_depth<=32の範囲を探索するように指定しています。
引数の詳細については、nameは任意の名前(引数名にしておいた方がいい)を指定し、引数のとる範囲をlowとhighに指定します。stepは、1の場合は引数のとる範囲の全てを使用し、2以上を指定した場合は、low, low+step, low+2*step, ...のように使用します。logは、引数の範囲が対数領域に変換され、サンプリングされて、元の領域に戻された値が使用されます。
min_samples_splitには、trial.suggest_float("min_samples_split", 0, 1,)が指定されており、min_samples_splitの探索範囲として、小数の0から1が指定されています。
Optunaのマニュアルのsuggest_float(https://optuna.readthedocs.io/en/stable/reference/generated/optuna.trial.Trial.html#optuna.trial.Trial.suggest_float)を見ると、suggest_float(name, low, high, *, step=None, log=False)とあり、suggest_int()とほぼ同じです。
objectiveメソッドの戻り値はAccuracy(分類精度)です。
スタディオブジェクトの作成と最適化の実行と結果表示
create_studyで、最大化を目的としたスタディオブジェクトが作られ、optimizeで実際に最適化を実行しています。最後に、最適化の結果、ベストの分類精度と、そのときに使用した引数を表示させています。
Optunaのマニュアルのcreate_study(https://optuna.readthedocs.io/en/stable/reference/generated/optuna.study.create_study.html#optuna.study.create_study)を見ます。引数のdirection="maximize"で、最大化の最適化を指定しています。
Optunaのマニュアルのoptimize(https://optuna.readthedocs.io/en/stable/reference/generated/optuna.study.Study.html#optuna.study.Study.optimize)を見ます。n_trials=100で、試行回数(ランダムフォレストの学習の回数)を指定しています。
OptunaのマニュアルのStudyクラス(https://optuna.readthedocs.io/en/stable/reference/generated/optuna.study.Study.html#optuna-study-study)を見ます。Attributes(属性)に、best_valueと、best_paramsがあり、それぞれの詳細の説明へのリンクがあります。この2つ以外にも、参照可能な属性が使用できることが分かります。
以下を実行します。
実行結果
実際にGoogle Colaboratoryで実行してみました。
[I 2024-03-18 16:48:07,908] A new study created in memory with name: no-name-0ee66a95-2f97-4355-a36b-c7dd40acc8c0
[I 2024-03-18 16:48:10,305] Trial 0 finished with value: 0.7607182349443268 and parameters: {'max_depth': 6, 'min_samples_split': 0.8390462700980509}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-18 16:48:13,301] Trial 1 finished with value: 0.762110464653306 and parameters: {'max_depth': 24, 'min_samples_split': 0.41546091404803887}. Best is trial 1 with value: 0.762110464653306.
[I 2024-03-18 16:48:15,060] Trial 2 finished with value: 0.7607182349443268 and parameters: {'max_depth': 29, 'min_samples_split': 0.969444032753063}. Best is trial 1 with value: 0.762110464653306.
[I 2024-03-18 16:48:16,843] Trial 3 finished with value: 0.7607182349443268 and parameters: {'max_depth': 7, 'min_samples_split': 0.9031391948680733}. Best is trial 1 with value: 0.762110464653306.
[I 2024-03-18 16:48:18,605] Trial 4 finished with value: 0.7607182349443268 and parameters: {'max_depth': 19, 'min_samples_split': 0.7612784794776261}. Best is trial 1 with value: 0.762110464653306.
・・・途中割愛・・・
[I 2024-03-18 16:59:45,564] Trial 95 finished with value: 0.8463617280781461 and parameters: {'max_depth': 21, 'min_samples_split': 0.02643139290358594}. Best is trial 84 with value: 0.8554113563787417.
[I 2024-03-18 16:59:51,495] Trial 96 finished with value: 0.8298390555991441 and parameters: {'max_depth': 26, 'min_samples_split': 0.10423539092493249}. Best is trial 84 with value: 0.8554113563787417.
[I 2024-03-18 17:00:00,539] Trial 97 finished with value: 0.841591241978196 and parameters: {'max_depth': 22, 'min_samples_split': 0.045115133886761236}. Best is trial 84 with value: 0.8554113563787417.
[I 2024-03-18 17:00:08,465] Trial 98 finished with value: 0.8340567274646876 and parameters: {'max_depth': 17, 'min_samples_split': 0.07261103742480408}. Best is trial 84 with value: 0.8554113563787417.
[I 2024-03-18 17:00:22,431] Trial 99 finished with value: 0.8547561884211966 and parameters: {'max_depth': 19, 'min_samples_split': 0.0011583420552988678}. Best is trial 84 with value: 0.8554113563787417.
Best objective value: 0.8554113563787417
Best parameter: {'max_depth': 23, 'min_samples_split': 0.0017140477373159217}
約12分かかり、100回の学習と評価で、ブラックボックス最適化を実行し、約0.85の分類精度となりました。書籍の結果より、少し低いですが、Optunaを使用してなかった場合の約0.76の分類精度から、大きく改善しました。
Optunaのスタディを再現させる
list_2_14_optimize_rf.pyをもう一度実行すると、以下のように、異なる結果が得られることが分かります。
[I 2024-03-19 14:38:36,453] A new study created in memory with name: no-name-ba409f79-d91c-47c6-90ac-36f4c8e3be61
[I 2024-03-19 14:38:39,240] Trial 0 finished with value: 0.7607182349443268 and parameters: {'max_depth': 3, 'min_samples_split': 0.4896570976010266}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:38:51,909] Trial 1 finished with value: 0.8513369845044804 and parameters: {'max_depth': 16, 'min_samples_split': 0.006380320617366264}. Best is trial 1 with value: 0.8513369845044804.
[I 2024-03-19 14:38:53,625] Trial 2 finished with value: 0.7607182349443268 and parameters: {'max_depth': 8, 'min_samples_split': 0.8767220264426059}. Best is trial 1 with value: 0.8513369845044804.
[I 2024-03-19 14:39:05,614] Trial 3 finished with value: 0.8519512061938818 and parameters: {'max_depth': 30, 'min_samples_split': 0.013673573424747842}. Best is trial 3 with value: 0.8519512061938818.
[I 2024-03-19 14:39:11,120] Trial 4 finished with value: 0.827095533646114 and parameters: {'max_depth': 11, 'min_samples_split': 0.16592141865436927}. Best is trial 3 with value: 0.8519512061938818.
・・・以降割愛・・・
全く同じ結果を得るためには、乱数シードの設定が必要です。Optunaの公式サイトのFAQに書かれています(https://optuna.readthedocs.io/en/stable/faq.html#how-can-i-obtain-reproducible-optimization-results)。
実際にやってみます。ソースコードの変更点は以下の通りです(これ以外は変更ありません)。
変更前
study = optuna.create_study(direction="maximize")
変更後
sampler = optuna.samplers.TPESampler(seed=0)
study = optuna.create_study(sampler=sampler, direction="maximize")
今回は乱数シードに0を設定しましたが、任意の整数を設定できます。
変更したlist_2_14_optimize_rf.pyを実行した結果は以下の通りです。
再度、list_2_14_optimize_rf.pyを実行します。
[I 2024-03-19 14:46:10,076] A new study created in memory with name: no-name-4c0f6c2a-fe7c-4fd3-94b8-0c1752aba146
[I 2024-03-19 14:46:12,393] Trial 0 finished with value: 0.7607182349443268 and parameters: {'max_depth': 19, 'min_samples_split': 0.7151893663724195}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:46:15,851] Trial 1 finished with value: 0.7607182349443268 and parameters: {'max_depth': 20, 'min_samples_split': 0.5448831829968969}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:46:17,725] Trial 2 finished with value: 0.7607182349443268 and parameters: {'max_depth': 15, 'min_samples_split': 0.6458941130666561}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:46:19,587] Trial 3 finished with value: 0.7607182349443268 and parameters: {'max_depth': 15, 'min_samples_split': 0.8917730007820798}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:46:22,920] Trial 4 finished with value: 0.7698905410762791 and parameters: {'max_depth': 31, 'min_samples_split': 0.3834415188257777}. Best is trial 4 with value: 0.7698905410762791.
・・・途中割愛・・・
[I 2024-03-19 14:57:09,656] Trial 95 finished with value: 0.8485934462026226 and parameters: {'max_depth': 18, 'min_samples_split': 0.021975518972960142}. Best is trial 82 with value: 0.8548585471747439.
[I 2024-03-19 14:57:25,576] Trial 96 finished with value: 0.8543466880116962 and parameters: {'max_depth': 21, 'min_samples_split': 0.00022872922730136322}. Best is trial 82 with value: 0.8548585471747439.
[I 2024-03-19 14:57:35,035] Trial 97 finished with value: 0.8389909634243521 and parameters: {'max_depth': 21, 'min_samples_split': 0.053218221319534575}. Best is trial 82 with value: 0.8548585471747439.
[I 2024-03-19 14:57:52,642] Trial 98 finished with value: 0.8537938637164729 and parameters: {'max_depth': 23, 'min_samples_split': 0.00018727384142899536}. Best is trial 82 with value: 0.8548585471747439.
[I 2024-03-19 14:57:58,945] Trial 99 finished with value: 0.8323778713634988 and parameters: {'max_depth': 24, 'min_samples_split': 0.08890826469424906}. Best is trial 82 with value: 0.8548585471747439.
Best objective value: 0.8548585471747439
Best parameter: {'max_depth': 18, 'min_samples_split': 0.00023055836175293556}
もう一度、同じソースコードで実行します。
[I 2024-03-19 14:59:04,918] A new study created in memory with name: no-name-ba4c001c-7cee-41a4-a29b-007c2702430c
[I 2024-03-19 14:59:06,863] Trial 0 finished with value: 0.7607182349443268 and parameters: {'max_depth': 19, 'min_samples_split': 0.7151893663724195}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:59:09,684] Trial 1 finished with value: 0.7607182349443268 and parameters: {'max_depth': 20, 'min_samples_split': 0.5448831829968969}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:59:11,386] Trial 2 finished with value: 0.7607182349443268 and parameters: {'max_depth': 15, 'min_samples_split': 0.6458941130666561}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:59:14,774] Trial 3 finished with value: 0.7607182349443268 and parameters: {'max_depth': 15, 'min_samples_split': 0.8917730007820798}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 14:59:18,428] Trial 4 finished with value: 0.7698087944218402 and parameters: {'max_depth': 31, 'min_samples_split': 0.3834415188257777}. Best is trial 4 with value: 0.7698087944218402.
・・・途中割愛・・・
[I 2024-03-19 15:11:43,799] Trial 95 finished with value: 0.8462798544058909 and parameters: {'max_depth': 29, 'min_samples_split': 0.027005809926542394}. Best is trial 71 with value: 0.856025578068143.
[I 2024-03-19 15:11:50,199] Trial 96 finished with value: 0.8296547653236431 and parameters: {'max_depth': 27, 'min_samples_split': 0.10525520375075349}. Best is trial 71 with value: 0.856025578068143.
[I 2024-03-19 15:11:53,330] Trial 97 finished with value: 0.7607182349443268 and parameters: {'max_depth': 28, 'min_samples_split': 0.5034699130716497}. Best is trial 71 with value: 0.856025578068143.
[I 2024-03-19 15:12:03,023] Trial 98 finished with value: 0.8413455442477001 and parameters: {'max_depth': 26, 'min_samples_split': 0.044533665120120094}. Best is trial 71 with value: 0.856025578068143.
[I 2024-03-19 15:12:11,240] Trial 99 finished with value: 0.8335653760197707 and parameters: {'max_depth': 24, 'min_samples_split': 0.08929905275628226}. Best is trial 71 with value: 0.856025578068143.
Best objective value: 0.856025578068143
Best parameter: {'max_depth': 28, 'min_samples_split': 0.001017849703871106}
最初の方は再現できているが、途中から結果が異なっています。
原因は、目的関数(objective)のランダムフォレストが乱数を使用しているため、その乱数シードが設定できていないためだと考えられます。
対策としては、乱数シード設定のメソッドの追加と、目的関数の先頭に追加した乱数シード設定メソッドの呼び出しを追加します。
追加
import random
def set_random_seed( seed ):
random.seed( seed )
np.random.seed( seed )
変更前
def objective(trial):
clf = RandomForestClassifier(
変更後
def objective(trial):
set_random_seed( 0 )
clf = RandomForestClassifier(
再度、list_2_14_optimize_rf.pyを実行します。
[I 2024-03-19 15:23:18,914] A new study created in memory with name: no-name-5194e802-dc00-4b23-bec7-4f2eedade006
[I 2024-03-19 15:23:21,402] Trial 0 finished with value: 0.7607182349443268 and parameters: {'max_depth': 19, 'min_samples_split': 0.7151893663724195}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 15:23:24,625] Trial 1 finished with value: 0.7607182349443268 and parameters: {'max_depth': 20, 'min_samples_split': 0.5448831829968969}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 15:23:26,529] Trial 2 finished with value: 0.7607182349443268 and parameters: {'max_depth': 15, 'min_samples_split': 0.6458941130666561}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 15:23:28,338] Trial 3 finished with value: 0.7607182349443268 and parameters: {'max_depth': 15, 'min_samples_split': 0.8917730007820798}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 15:23:31,842] Trial 4 finished with value: 0.7693788064158434 and parameters: {'max_depth': 31, 'min_samples_split': 0.3834415188257777}. Best is trial 4 with value: 0.7693788064158434.
・・・途中割愛・・・
[I 2024-03-19 15:36:32,049] Trial 95 finished with value: 0.841816464688217 and parameters: {'max_depth': 27, 'min_samples_split': 0.040705958355933866}. Best is trial 59 with value: 0.85592318661694.
[I 2024-03-19 15:36:40,530] Trial 96 finished with value: 0.8340363065211047 and parameters: {'max_depth': 26, 'min_samples_split': 0.07378979605757345}. Best is trial 59 with value: 0.85592318661694.
[I 2024-03-19 15:36:47,251] Trial 97 finished with value: 0.8297980829213555 and parameters: {'max_depth': 25, 'min_samples_split': 0.11078448646792491}. Best is trial 59 with value: 0.85592318661694.
[I 2024-03-19 15:36:57,877] Trial 98 finished with value: 0.8491872117355811 and parameters: {'max_depth': 25, 'min_samples_split': 0.018643125560272363}. Best is trial 59 with value: 0.85592318661694.
[I 2024-03-19 15:37:02,268] Trial 99 finished with value: 0.7722042573756228 and parameters: {'max_depth': 26, 'min_samples_split': 0.35128774524331274}. Best is trial 59 with value: 0.85592318661694.
Best objective value: 0.85592318661694
Best parameter: {'max_depth': 27, 'min_samples_split': 0.0010546408626361447}
もう一度、同じソースコードで実行します。
[I 2024-03-19 15:39:07,592] A new study created in memory with name: no-name-bf81351c-ea09-4557-9b2e-8b8a34444c7a
[I 2024-03-19 15:39:09,480] Trial 0 finished with value: 0.7607182349443268 and parameters: {'max_depth': 19, 'min_samples_split': 0.7151893663724195}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 15:39:12,507] Trial 1 finished with value: 0.7607182349443268 and parameters: {'max_depth': 20, 'min_samples_split': 0.5448831829968969}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 15:39:14,251] Trial 2 finished with value: 0.7607182349443268 and parameters: {'max_depth': 15, 'min_samples_split': 0.6458941130666561}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 15:39:16,797] Trial 3 finished with value: 0.7607182349443268 and parameters: {'max_depth': 15, 'min_samples_split': 0.8917730007820798}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-19 15:39:20,703] Trial 4 finished with value: 0.7693788064158434 and parameters: {'max_depth': 31, 'min_samples_split': 0.3834415188257777}. Best is trial 4 with value: 0.7693788064158434.
・・・途中割愛・・・
[I 2024-03-19 15:51:55,304] Trial 95 finished with value: 0.841816464688217 and parameters: {'max_depth': 27, 'min_samples_split': 0.040705958355933866}. Best is trial 59 with value: 0.85592318661694.
[I 2024-03-19 15:52:03,229] Trial 96 finished with value: 0.8340363065211047 and parameters: {'max_depth': 26, 'min_samples_split': 0.07378979605757345}. Best is trial 59 with value: 0.85592318661694.
[I 2024-03-19 15:52:09,515] Trial 97 finished with value: 0.8297980829213555 and parameters: {'max_depth': 25, 'min_samples_split': 0.11078448646792491}. Best is trial 59 with value: 0.85592318661694.
[I 2024-03-19 15:52:20,484] Trial 98 finished with value: 0.8491872117355811 and parameters: {'max_depth': 25, 'min_samples_split': 0.018643125560272363}. Best is trial 59 with value: 0.85592318661694.
[I 2024-03-19 15:52:24,925] Trial 99 finished with value: 0.7722042573756228 and parameters: {'max_depth': 26, 'min_samples_split': 0.35128774524331274}. Best is trial 59 with value: 0.85592318661694.
Best objective value: 0.85592318661694
Best parameter: {'max_depth': 27, 'min_samples_split': 0.0010546408626361447}
同じスタディを再現できました。
list_2_16_optimize_rf_gb_with_conditional_search_space.py
list_2_16_optimize_rf_gb_with_conditional_search_space.py(https://github.com/dk0893/optuna-book/blob/master/chapter2/list_2_16_optimize_rf_gb_with_conditional_search_space.py)では、複数のモデルを使う方法が実装されています。
具体的には、RandomForestClassifierに加えて、scikit-learnのGradientBoostingClassifierの2つのモデルが使用されており、さらに、スタディを作成するときに、スタディ名とストレージを指定することで、SQLiteのデータベースを作成し、このデータベースに実行結果を登録しています。
スタディオブジェクトの作成と最適化の実行と結果表示
今回は、データベースについて深堀したいため、モデルのところはlist_2_14_optimize_rf.pyのままとし、データベースを使用するところだけを採用して、実行してみます。以下に、list_2_14_optimize_rf.pyから変更した箇所を示します。
変更前
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=100)
print(f"Best objective value: {study.best_value}")
print(f"Best parameter: {study.best_params}")
変更後
study = optuna.create_study(
study_name="ch2-rf-seed",
storage="sqlite:///optuna.db",
direction="maximize")
study.optimize(objective, n_trials=100)
print(f"Best objective value: {study.best_value}")
print(f"Best parameter: {study.best_params}")
Optunaのマニュアルのcreate_study(https://optuna.readthedocs.io/en/stable/reference/generated/optuna.study.create_study.html#optuna.study.create_study)を見ます。
引数のstudy_name="ch2-rf-seed"で、スタディ名を指定しています。指定しなくても、ユニークな名前が自動で付けられますが、後で見たときに分かりやすいため、指定した方がいいでしょう。
引数のstorage="sqlite:///optuna.db"で、SQLiteのデータベースファイル名(ストレージ)を指定しており、まだデータベースファイルが存在していない場合は、カレントディレクトリにoptuna.dbというファイル名でデータベースファイルが作成されます。
storage引数を指定しない場合、今回実行したスタディはどこにも保存されません。
その場合、一番良かったハイパーパラメータでもう一度学習をしたい場合、そのパラメータをprint文で表示していれば、それを見て、そのパラメータを設定すれば、同じパラメータで学習することが出来るかもしれません。しかし、浮動小数点数のパラメータの場合、print文で全てが表示されていない場合があるので、全くパラメータを設定することが出来ず、学習を再現することはできないかもしれません。
データベースと言っても、そこまで大きなファイルになるわけではないので、storage引数を指定して、いつもストレージにスタディの結果を保存するようにした方がいいでしょう。
また、データベースファイルを作成しておけば、Optuna Dashboardが使えます。
Optuna Dashboardでは、ブラウザ上で実行したスタディについて、様々な分析が行えます。使い方については、別の記事を書いたので、良かったら参考にしてください。
daisuke20240310.hatenablog.com
実行結果
[I 2024-03-20 06:01:37,398] A new study created in RDB with name: ch2-rf-seed
[I 2024-03-20 06:01:40,190] Trial 0 finished with value: 0.7607182349443268 and parameters: {'max_depth': 18, 'min_samples_split': 0.5638938133595764}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-20 06:01:42,109] Trial 1 finished with value: 0.7607182349443268 and parameters: {'max_depth': 32, 'min_samples_split': 0.788055583212047}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-20 06:01:45,104] Trial 2 finished with value: 0.7607182349443268 and parameters: {'max_depth': 27, 'min_samples_split': 0.6024974755098238}. Best is trial 0 with value: 0.7607182349443268.
[I 2024-03-20 06:01:50,297] Trial 3 finished with value: 0.8142785254725554 and parameters: {'max_depth': 5, 'min_samples_split': 0.14468519929589163}. Best is trial 3 with value: 0.8142785254725554.
[I 2024-03-20 06:01:53,740] Trial 4 finished with value: 0.7720404672726398 and parameters: {'max_depth': 12, 'min_samples_split': 0.3523860798470476}. Best is trial 3 with value: 0.8142785254725554.
・・・途中割愛・・・
[I 2024-03-20 06:13:55,242] Trial 95 finished with value: 0.8302075581788131 and parameters: {'max_depth': 19, 'min_samples_split': 0.09428362784266728}. Best is trial 72 with value: 0.8554523013892831.
[I 2024-03-20 06:13:59,747] Trial 96 finished with value: 0.7684779570766304 and parameters: {'max_depth': 20, 'min_samples_split': 0.391099669378463}. Best is trial 72 with value: 0.8554523013892831.
[I 2024-03-20 06:14:08,315] Trial 97 finished with value: 0.8446419319968242 and parameters: {'max_depth': 15, 'min_samples_split': 0.03303767220036553}. Best is trial 72 with value: 0.8554523013892831.
[I 2024-03-20 06:14:16,474] Trial 98 finished with value: 0.8342410227705971 and parameters: {'max_depth': 25, 'min_samples_split': 0.0714018376653957}. Best is trial 72 with value: 0.8554523013892831.
[I 2024-03-20 06:14:22,132] Trial 99 finished with value: 0.8282010992348194 and parameters: {'max_depth': 17, 'min_samples_split': 0.12281022399304492}. Best is trial 72 with value: 0.8554523013892831.
Best objective value: 0.8554523013892831
Best parameter: {'max_depth': 23, 'min_samples_split': 0.0009062357253867216}
スタディをストレージに保存する機能を追加した以外は、list_2_14_optimize_rf.pyから変更してないので、先ほどと同じような結果になりました。
create_studyメソッドの引数のload_if_existsの説明を追加
今回は引数のload_if_existsを指定していませんでした。この引数は、データベースファイルを使う場合は必要になる場合があるので、ここで説明します。
load_if_existsのデフォルトはFalseです。
load_if_exists=Falseでcreate_studyを実行した場合、ストレージに既に同じ名前のスタディが存在した場合、以下のようにエラーが発生し、ストレージに保存したスタディを壊さないようにしてくれます。
DuplicatedStudyError: Another study with name 'ch2-rf-seed' already exists. Please specify a different name, or reuse the existing one by setting `load_if_exists` (for Python API) or `--skip-if-exists` flag (for CLI).
一方、load_if_exists=Trueでcreate_studyを実行し、optimizeを実行した場合、指定したスタディの続きからトライアルを実行してくれます(最初にoptimizeでn_trialsを100で実行していた場合、101回目から続きを実行してくれます)。
以下を実行
study = optuna.create_study(
study_name="ch2-rf-seed",
storage="sqlite:///optuna.db",
direction="maximize",
load_if_exists=True)
study.optimize(objective, n_trials=100)
print(f"Best objective value: {study.best_value}")
print(f"Best parameter: {study.best_params}")
実行結果
[I 2024-03-20 06:22:48,549] Using an existing study with name 'ch2-rf-seed' instead of creating a new one.
[I 2024-03-20 06:22:58,802] Trial 100 finished with value: 0.8464231581699796 and parameters: {'max_depth': 14, 'min_samples_split': 0.021362272594642306}. Best is trial 72 with value: 0.8554523013892831.
[I 2024-03-20 06:23:10,816] Trial 101 finished with value: 0.8517054858265473 and parameters: {'max_depth': 18, 'min_samples_split': 0.009011066100582318}. Best is trial 72 with value: 0.8554523013892831.
[I 2024-03-20 06:23:19,036] Trial 102 finished with value: 0.8403218397552283 and parameters: {'max_depth': 19, 'min_samples_split': 0.04818164005763597}. Best is trial 72 with value: 0.8554523013892831.
[I 2024-03-20 06:23:29,129] Trial 103 finished with value: 0.8475492541136544 and parameters: {'max_depth': 20, 'min_samples_split': 0.02326090335375395}. Best is trial 72 with value: 0.8554523013892831.
[I 2024-03-20 06:23:42,828] Trial 104 finished with value: 0.8543467093909327 and parameters: {'max_depth': 18, 'min_samples_split': 0.0016971833803444691}. Best is trial 72 with value: 0.8554523013892831.
・・・途中割愛・・・
[I 2024-03-20 06:39:40,899] Trial 195 finished with value: 0.8425330476463699 and parameters: {'max_depth': 28, 'min_samples_split': 0.03683044981939044}. Best is trial 178 with value: 0.8559231929049508.
[I 2024-03-20 06:39:51,507] Trial 196 finished with value: 0.8482044296168122 and parameters: {'max_depth': 27, 'min_samples_split': 0.019320595313816837}. Best is trial 178 with value: 0.8559231929049508.
[I 2024-03-20 06:40:08,113] Trial 197 finished with value: 0.8553703824433508 and parameters: {'max_depth': 25, 'min_samples_split': 0.000783018066616531}. Best is trial 178 with value: 0.8559231929049508.
[I 2024-03-20 06:40:15,712] Trial 198 finished with value: 0.838929610046249 and parameters: {'max_depth': 25, 'min_samples_split': 0.05273723875182029}. Best is trial 178 with value: 0.8559231929049508.
[I 2024-03-20 06:40:25,736] Trial 199 finished with value: 0.8434134320259252 and parameters: {'max_depth': 26, 'min_samples_split': 0.034967023097725466}. Best is trial 178 with value: 0.8559231929049508.
Best objective value: 0.8559231929049508
Best parameter: {'max_depth': 24, 'min_samples_split': 0.0006325520315008212}
追加でさらに100回トライアルを実行したが、精度の改善はわずかでした。探索空間が2つの引数のみであり、片方が離散値なので、選択肢が少ないことが原因だと思われます。
list_2_19_load_study.pyを実行する
list_2_19_load_study.pyのソースコードは以下の通りです。
説明しやすいように、一部コメントを追加しています。また、学習を再現するためにベストトライアルの番号の表示も追加しています。
処理の内容は、ストレージとスタディ名を指定して、スタディをデータベースからロードしています。
import optuna
study = optuna.load_study(
study_name="ch2-rf-seed",
storage="sqlite:///optuna.db",
)
print(f"Best objective value: {study.best_value}")
print(f"Best parameter: {study.best_params}")
print(f"Best number: {study.best_trial.number}")
スタディのロード
Optunaのマニュアルのload_study(https://optuna.readthedocs.io/en/stable/reference/generated/optuna.study.load_study.html)を見ます。create_studyと同じく、引数にstudy_name="ch2-rf-seed"でスタディ名を、storage="sqlite:///optuna.db"でデータベースファイルパスを指定しています。
実行結果
Best objective value: 0.8559231929049508
Best parameter: {'max_depth': 24, 'min_samples_split': 0.0006325520315008212}
Best number: 178
スタディを実行した結果と同じ内容を読み出すことができています。
Optunaで探索したベストパラメータを使って、学習を再現する
まず、ソースコードを示します。
tr = study.trials[study.best_trial.number]
set_random_seed( 0 )
clf = RandomForestClassifier(
max_depth=tr.params['max_depth'],
min_samples_split=tr.params['min_samples_split'],
)
score = cross_val_score(clf, X, y, cv=3)
accuracy = score.mean()
print(f"Accuracy: {accuracy}")
ここでは、どのトライアルを参照する場合にでも使える方法として、best_trial.numberで対象のトライアルを参照して、そのトライアルのparamsを使っていますが、単純にベストパラメータを指定したいだけなら、study.best_paramsで参照できます。
OptunaのマニュアルのStudyクラス(https://optuna.readthedocs.io/en/stable/reference/generated/optuna.study.Study.html)を見ます。
Attributesに、「list_2_19_load_study.pyを実行する」でも使用した、best_trialがあり、ベストパラメータのトライアルが参照できます。以下は、best_trialを参照した結果です。
FrozenTrial(number=178, state=TrialState.COMPLETE, values=[0.8559231929049508], datetime_start=datetime.datetime(2024, 3, 20, 6, 36, 4, 44871), datetime_complete=datetime.datetime(2024, 3, 20, 6, 36, 20, 969838), params={'max_depth': 24, 'min_samples_split': 0.0006325520315008212}, user_attrs={}, system_attrs={}, intermediate_values={}, distributions={'max_depth': IntDistribution(high=32, log=False, low=2, step=1), 'min_samples_split': FloatDistribution(high=1.0, log=False, low=0.0, step=None)}, trial_id=389, value=None)
これを見ると、best_trialのnumberを参照すると、トライアル番号が参照できることが分かります。
また、trialsがあり、スタディの全トライアルをリストで返してくれます。best_trialで参照したトライアルで、numberで、トライアル番号を参照することで、ベストパラメータを参照することができます。
実行結果
Accuracy: 0.8559231929049508
ベストパラメータの学習が再現できていることが分かります。
今回は以上です。お疲れ様でした!