Webスクレイピングとは、プログラムを使用して、Webサイトの情報(データ)をダウンロードし、データを解析、分析することを言います。
初回なので、スクレイピングをするにあたっての注意事項や基本的なところを書きます。
あまり無茶は出来ませんが、スクレイピングを使うと、とても便利なことがあると思います。
例えば、自分のブログのリンク切れ自動チェックや、ブログ記事一覧の自動作成、URLを入力すると記事タイトルを表示させるツール(URLを投稿日時にしてしまった場合に便利)など、ブログ運営に役に立ちそうなことが出来そうです。
今回は、自分のブログの記事のURLとタイトルの一覧を取得できるツールを作ってみたいと思います。
それでは、やっていきます!
クローリングとは
ネット上に公開されているデータを集めることをクローニングと言います。
また、この集めたデータを解析して、必要な情報を取得することをスクレイピングと言います。
クローリング禁止について知る
著作権を守ることや、過度なアクセスをしない、ということは前提として理解しているとします。
サイトがクローリングを禁止しているかどうかは、「robots.txt」と、各ページの「robots metaタグ」を見ると分かります。
robots.txtを見てみる
自分のブログの「robots.txt」を見てみる。
「robots.txt」は、自分のブログのルートディレクトリに置いてあります。
例えば、このブログの場合、トップページのURL(例えば、https://daisuke20240310.hatenablog.com/)に「robots.txt」を付けて、https://daisuke20240310.hatenablog.com/robots.txt にアクセスすると、以下のような内容が表示されます。
User-agent: *
Sitemap: https://daisuke20240310.hatenablog.com/sitemap_index.xml
Disallow: /api/
Disallow: /draft/
Disallow: /preview
User-agent: Mediapartners-Google
Disallow: /draft/
Disallow: /preview
Disallow と書かれたところはクローリング(データを集めること)禁止という意味になります。
まずは、User-agent: * を見ておけばいいです(User-agent: Mediapartners-Google 以降はよく分かりません)。
つまり、apiディレクトリ、draftディレクトリ、previewディレクトリはクローリング禁止ということになります。
自分のブログのトップページの「robots metaタグ」を見てみます。
自分のブログのトップページを開きます。
右クリックで「ページのソースを表示」(Chromeの場合)をクリックします。
Ctrl+Fを押して、「robots」を検索します。
私のブログの場合、以下が見つかりました。
<meta name="robots" content="max-image-preview:large" />
robots metaタグには、以下のようなものがあるようです。
robots metaタグ
・index:インデックス可
・noindex:インデックス不可
・follow:リンクを辿ってOK
・nofollow:リンクを辿ってはダメ
・noarchive:Webページをキャッシュさせない
・nosnippet:検索結果にテキストスニペット(meta description)を表示させない
・max-snippet:テキストスニペットを指定した値の文字数に制限する
・max-image-preview:検索結果に表示されるページの画像プレビューの大きさ(none:画像なし、standard:デフォルト画像、large:画面の横幅までの画像)
・max-video-preview:動画の場合のプレビュー秒数の指定
・unavailable_after:検索結果に表示する最後の日時を指定(以降は表示されない)
・noimageindex:画像のインデックス禁止
特に禁止はしてなさそうです。
クローニングをやってみる
事前準備
Pythonは既にインストールされているものとします。
Pythonに2つのライブラリをインストールします。
1つは、「requests」で、Webページを便利に取得できるライブラリです。
もう1つは、「beautifulsoup4」で、HTMLからデータを取得、解析するライブラリです。
コマンドプロンプトなどで、以下を実行します。
pip install requests beautifulsoup4
では、準備できましたので、早速やっていきます!
クローニングしてみる
今回は、WindowsのIDLEを使ってみます。
まずは、自分のトップページを取得してみます。
IDLEのFile→New Fileで、untitledというエディタが開くので、適当な場所に名前を付けて保存します(例:cloning.py)。
以下を入力して保存します(File→Save、または、Ctrl+s)。
import requests
url = "https://daisuke20240310.hatenablog.com"
response = requests.get( url )
response.encoding = response.apparent_encoding
print( response.text )
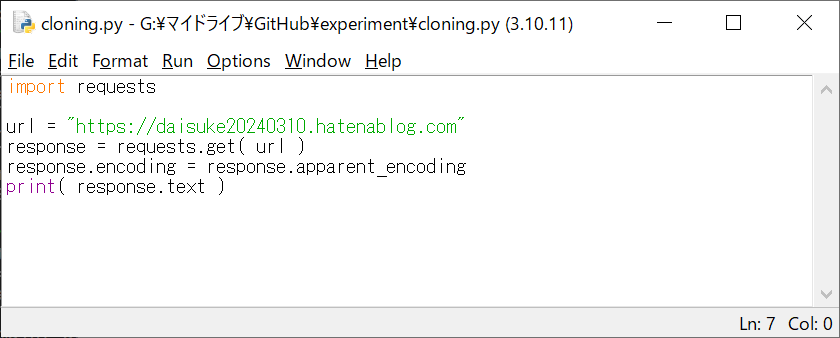 cloning.py
cloning.py
Run→Run Moduleで実行できます。
 実行結果
実行結果
黄色の箱の「Squeezed text (3243 lines).」をダブルクリックすると、長いけど表示する?と聞かれるので、OKを押すと取得したデータが全て見れます。
 実行結果(展開後)
実行結果(展開後)
自分のブログのトップページのデータが取得できました。
スクレイピングをやってみる
では、取得できたデータを解析していきましょう!(スクレイピング)
aタグとtitleタグを1つずつ取得する
まずは、リンクを取得してみます。
ソースコードと結果を示します。
import requests
from bs4 import BeautifulSoup
url = "https://daisuke20240310.hatenablog.com"
response = requests.get( url )
response.encoding = response.apparent_encoding
parse_html = BeautifulSoup( response.text, "html.parser" )
print( parse_html.find("a") )
print( parse_html.find("title") )
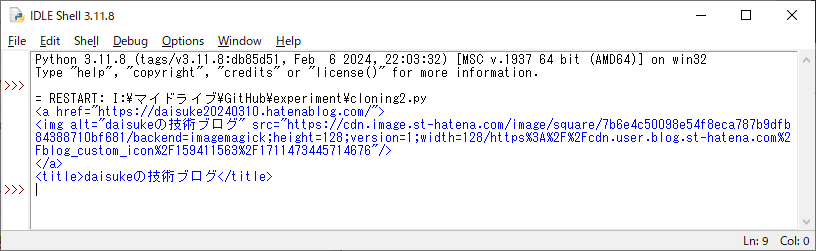 実行結果2
実行結果2
BeautifulSoupで、取得したデータを解析してくれます。第1引数には取得したデータを指定し、第2引数はHTMLパーサーの指定で、他のパーサーも指定できますが、まずはこれを指定しています。
parse_html は、BeautifulSoupのオブジェクトで、これを使って、解析した結果を取得できます。find("a") メソッドは、先頭のaタグを1つ取得できます。
aタグの内容を見ると、URLはトップページで、リンクテキストには画像のURLが入っているようです。ブログのタイトルが先頭かな?と思ったのですが、違ったようです。
分からないので、Chromeのデベロッパーツールで確認してみます。
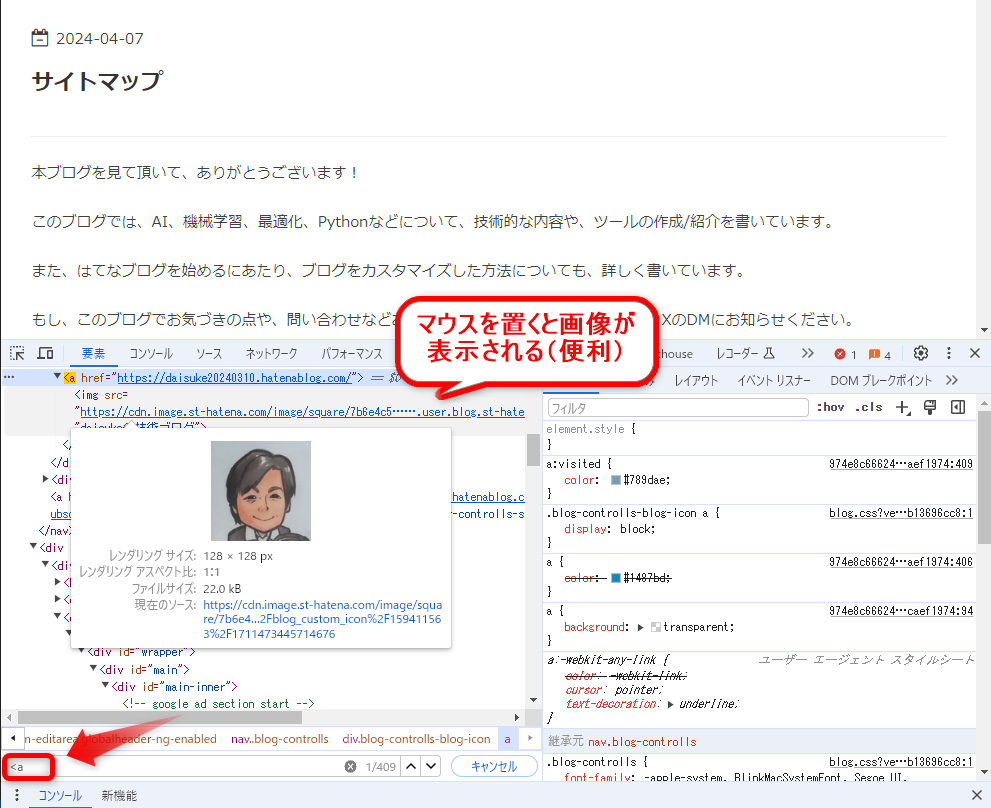 デベロッパーツールで確認
デベロッパーツールで確認
bodyタグの先頭あたりから <a で検索すると、なるほど、プロフィールの画像だったんですね、納得です。
今回は、find("a") を使いましたが、find_all("a") とすると、全てのaタグをリストで取得できます。
もう一つのtitleタグは、普通にタイトルが取得できています。
サイト内の全URLを取得する
リンクが取得できたので、あとは再帰的にリンクをたどれば、サイト内の全URLを取得できそうです。
ただし、外部のURLは対象外にしないと永遠と取得し続けてしまうので、注意が必要です。
実装しようかと思ったのですが、今回は ChatGPT に実装してもらおうと思います!
daisuke20240310.hatenablog.com
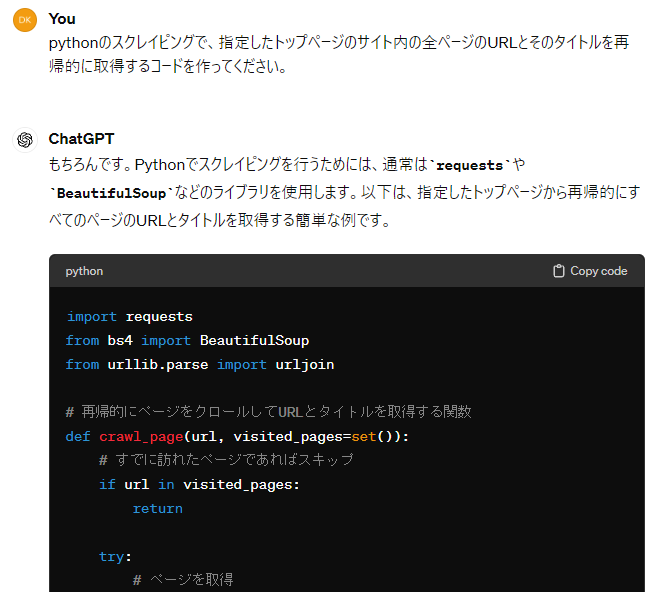 ChatGPTに実装をお願いしてみる
ChatGPTに実装をお願いしてみる
 ChatGPTに実装をお願いしてみる2
ChatGPTに実装をお願いしてみる2
ChatGPT、ヤバすぎです!
少し意図したものではないのですが、十分使えるコードがタダで出てきました(笑)
ChatGPTの出力したコードと実行結果を貼っておきます。
このままだと連続でサイトにアクセスしてしまい、サーバに負担がかかる可能性があるので、適宜、数秒のsleep入れるなどの必要があると思います。
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
def crawl_page(url, visited_pages=set()):
if url in visited_pages:
return
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.text.strip()
print(f"URL: {url} - タイトル: {title}")
visited_pages.add(url)
for link in soup.find_all('a', href=True):
absolute_link = urljoin(url, link['href'])
if absolute_link.startswith("http://example.com"):
crawl_page(absolute_link, visited_pages)
except Exception as e:
print(f"エラーが発生しました: {e}")
start_url = "http://example.com"
crawl_page(start_url)
 実行結果3
実行結果3
アンカーリンク(ページ内リンク)を含んでしまってるので、それは除外するコードを追加する必要がありますね。
ChatGPTにお願いする内容の精度を上げる必要がありそうです(笑)
今回は以上です!
終わりに
それにしても、ChatGPTのコード生成の精度は衝撃でした。
Pythonの細かい文法は既に覚えなくていいですね。今後もたくさん活用していこうと思います。
最後までお読みいただき、ありがとうございました。